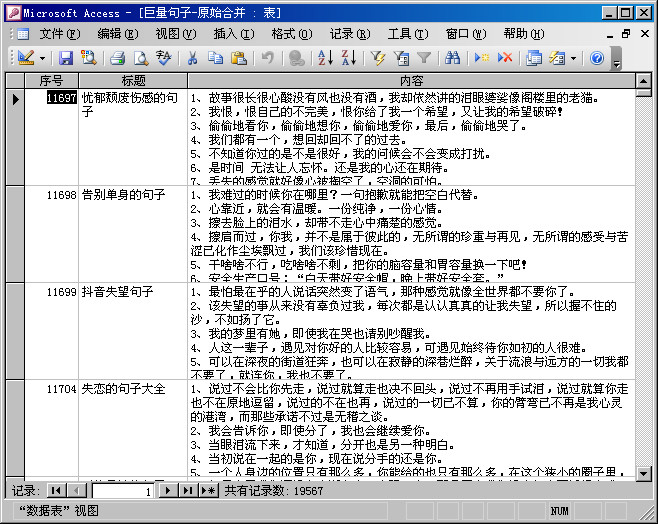
今天从某个网站采集了近2万个经典句子类内容,但这个内容不是以一个句子的方式而是一批句子的方式保存在一个内容字段中,如下图:
这种方式只能用于文章型的浏览,利用率不太高,因此编写程序把内容的一句一句提取出来,并且进行了一些整理,最后形成具有33万多记录的表,如下图:
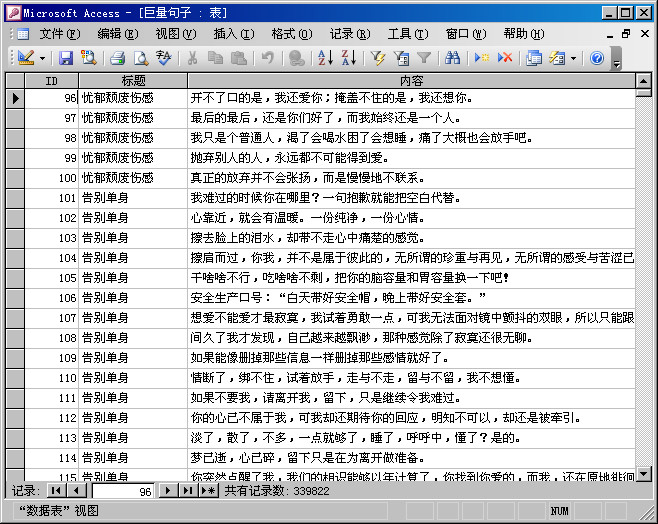
具体说一下整理的工作:1.初始整理成行共150多万条记录;2.去除行头序号;3.去除含**敏感词的记录;4.去除10字以下155字以上的记录;5.去除某些不佳句子;6.去除重复的记录,到第6步之后记录集只剩下33万多了。 标题也适当的整理了一下,GROUP BY后有9千多。
数据提供ACCESS创建的MDB扩展名文件以及EXCEL创建的XLS扩展名文件。
这种方式只能用于文章型的浏览,利用率不太高,因此编写程序把内容的一句一句提取出来,并且进行了一些整理,最后形成具有33万多记录的表,如下图:
具体说一下整理的工作:1.初始整理成行共150多万条记录;2.去除行头序号;3.去除含**敏感词的记录;4.去除10字以下155字以上的记录;5.去除某些不佳句子;6.去除重复的记录,到第6步之后记录集只剩下33万多了。 标题也适当的整理了一下,GROUP BY后有9千多。
数据提供ACCESS创建的MDB扩展名文件以及EXCEL创建的XLS扩展名文件。
购买联系
| QQ 36498753 | 微信 WebDataBase | 旺旺 linshengling | 支付宝 linshengling@163.com |